
This article was originally published on multilingual.com.
Optical character recognition, or OCR, is an important step in preparing documents for localization. It requires thorough text processing before submitting a document to the translator. The reason why one should pay attention to document preparation is that not all documents can be edited directly. OCR tools may be required to convert files into an editable format.
In this article, we delve into the intricacies of preparing documents for translation and ascertain how AI can improve the quality, speed, and cost-effectiveness of this process.

Figure 1. A schematic illustration of OCR process
In the context of this article, optical character recognition is a step in preparing documents for translation. It involves converting non-editable versions of documents (such as PDF, JPG, or TIFF files) into editable versions compatible with CAT tools for subsequent translation.
Various automated image and text recognition tools such as ABBYY FineReader, Adobe Acrobat, and Expert PDF are used for this purpose. To ensure compatibility with CAT tools:

Figure 2. CAT tool compatibility criteria
The document structure is also crucial. Pay attention to:
All of these factors ensure high quality and faster processing of the document both before and after its translation.
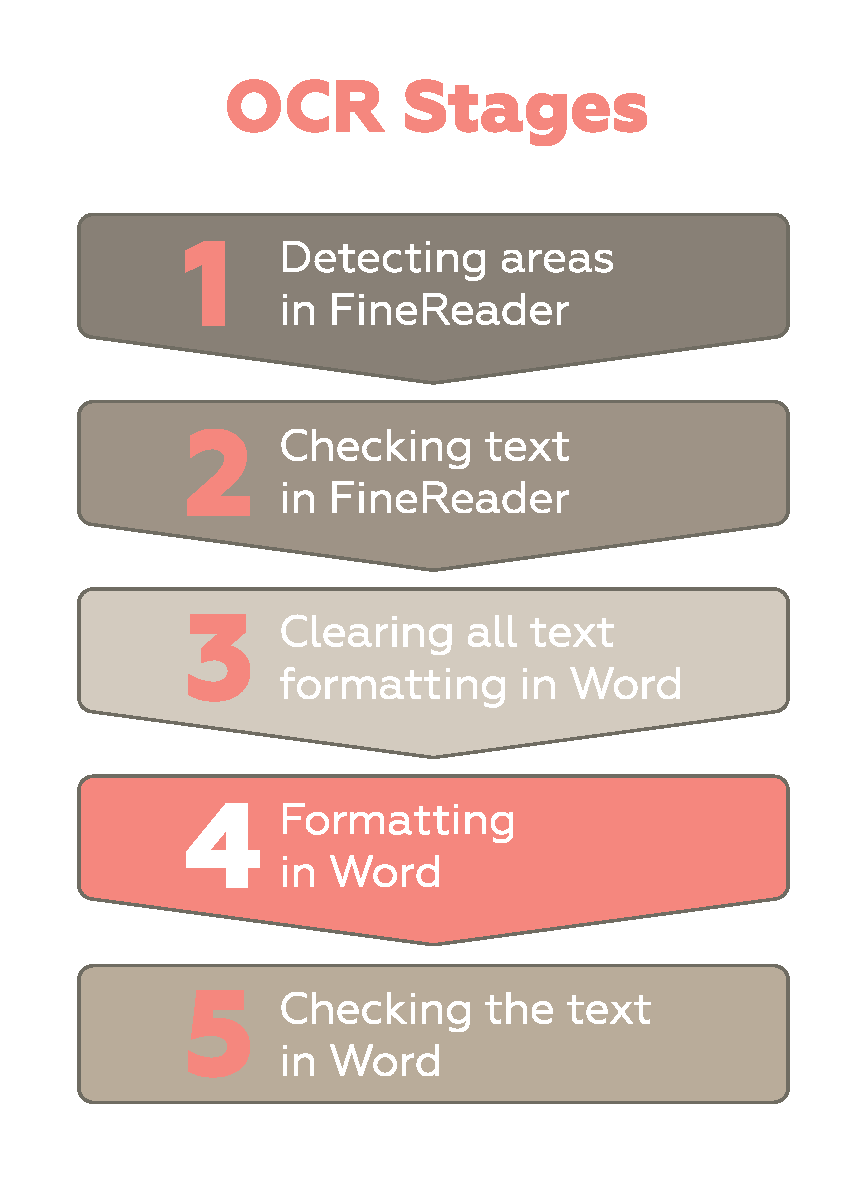
Figure 3. The stages of OCR
In this stage, recognition areas are detected in accordance with the purpose of the element: table, main text, image, background image with captions.
This process can be performed either automatically or manually. Note that a fully automated process may leave some text unrecognized or the destination incorrectly set. You can speed up the work by using area templates for identical layouts.
FineReader contains a built-in module for checking dubiously recognized characters. This step is performed by an operator who visually matches fragments that FineReader has detected as incorrectly recognized.
After transferring the recognized document to Word, it is essential to clear all unnecessary formatting. This helps to prevent excessive tags in CAT tools that can hinder the translator’s work and pollute translation memory. You can use macros to automate this process.
Adjust page settings, headers, footers, styles, and lists, and make the document as a whole look as similar as possible to the original. This is a mostly manual task, with hardly any room for automation.
Check spelling and numbers. You can optimize this step by using macros to highlight individual digits, periods, commas, and other special characters, considerably speeding up the checking process.
AI should target the most time-consuming step or steps with a high error probability.
The rough ranking of steps by duration is the following, starting from the most labor-intensive:
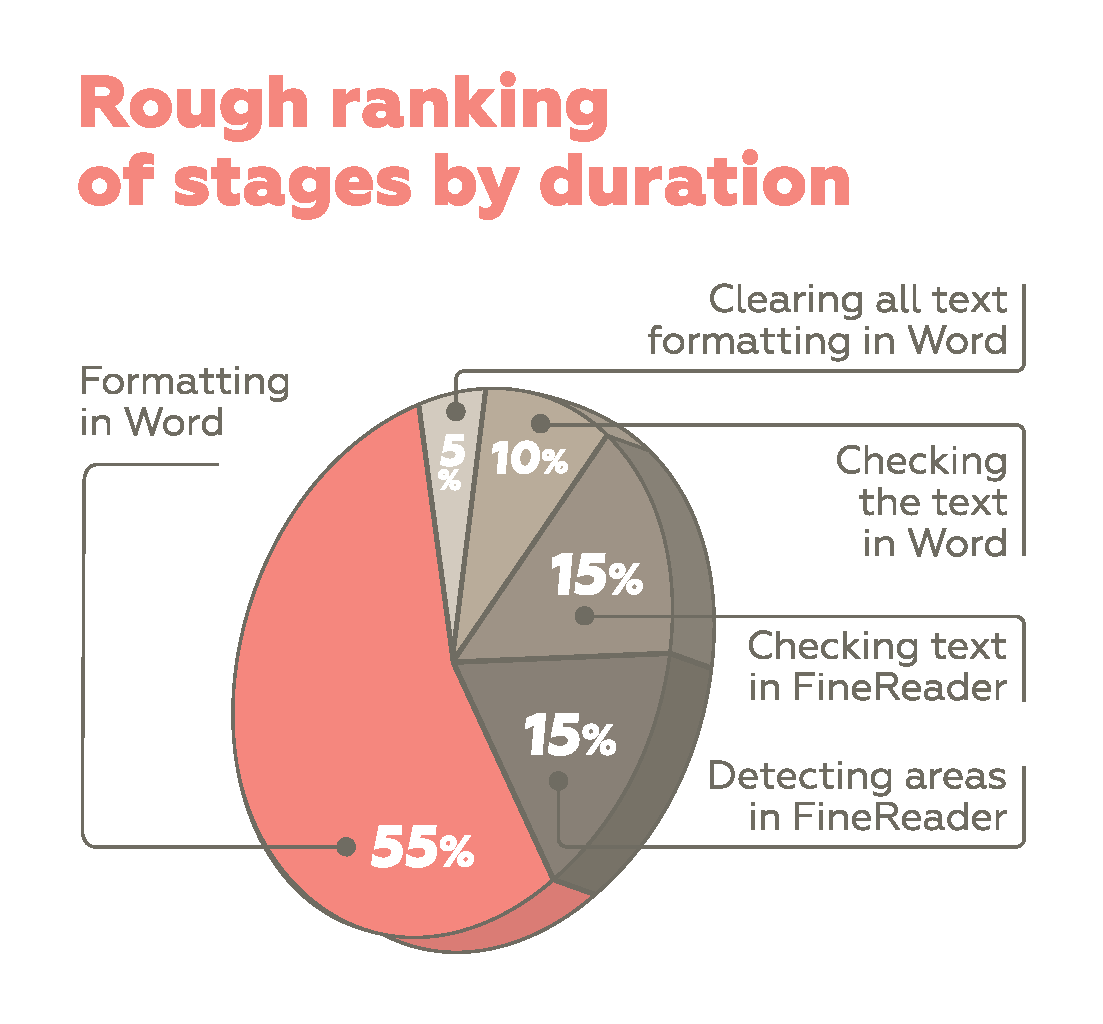
Figure 4. Rough ranking of stages by duration
Let’s have a look at how to use AI in each tool.
During the recognition process, FineReader uses AI-based recognition technologies. There is currently no way to improve the automatic area detection feature to speed up this step with the use of existing software. At the same time, FineReader continues to evolve, and we expect that future functionality will allow us to apply AI ourselves.
The most time-consuming formatting step is completely manual and requires a visual comparison to the original.
One way to use AI with an already recognized document would be to incorporate it in the checking process for any spelling, number, and single-character errors. Computer vision technologies are already available. However, it remains uncertain whether an AI tool capable of comparing the original image with recognized text will evolve in the near future.
Using artificial intelligence to verify recognized text without an original image is not very effective. Since there is no access to the original text, the AI has no information about what the recognized text or numbers should be. A true AI gamechanger in this area will be able to compare the original text to the recognized version.
While artificial intelligence can potentially improve some aspects of document preparation for translation, such as spelling and character recognition, current software functionality limits its ability to fully replace the verification stage done by humans.
That said, the opportunity to apply AI to OCR exists and continues to evolve. The underlying question is whether there will be sufficient long-term demand. Assuming that the volume of content requiring OCR decreases as digitalization progresses, the need for OCR will diminish as well.
However, demand for OCR is still strong owing to widespread use of the PDF format. And currently, all indications are that this file format will continue to be regularly used by people all over the world.
Want to discuss a topic or share your experience or opinion? Reach out to us at localize@intext.com or dtp.intext.com!